Schools or large companies with hundreds of users can easily accumulate terabytes of Google Apps data, including tens of millions of Gmail messages. This presents a serious problem for backup strategies – the initial backup may take months or even longer!
One reason for this is that CubeBackup performs user backups one by one in a non-parallel manner. We plan to include parallel backup algorithm in the next version of CubeBackup, but in the meantime, there are still methods that can be used to greatly speed up large backups by working with the user data in parallel.
Before presenting some of these solutions, I’d like to give an introduction to how backup data is saved locally. Simply put, all backup data for each user, including the actual Google Apps data and metadata used to record the backup progress for each user, are stored in that user’s own directory. For example, data for user “[email protected]” would be stored in the directory “[email protected]” like this:
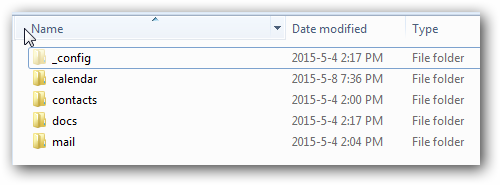
Folders like “calendar”, “contacts”, “docs”, and “mail” are used to store the actual backup data for Google Apps. There is also a hidden folder named “_config”, which is used to record important metadata, like timestamps for the last backup, the cloud ID of the local backup files, etc. CubeBackup itself only stores general settings for the whole app, all user data, whether actual backup data or metadata to describe a user’s current status, are stored in that user’s own directory.
This design makes the backup data very portable, as well as bringing an extra benefit: several CubeBackup instances can run simultaneously while sharing the same local storage. This means that, for large companies with hundreds of employees, the best way to speed up the backup process is to split the users into separate CubeBackup instances on different computers. Let me illuminate this method with a specific example:
An Example
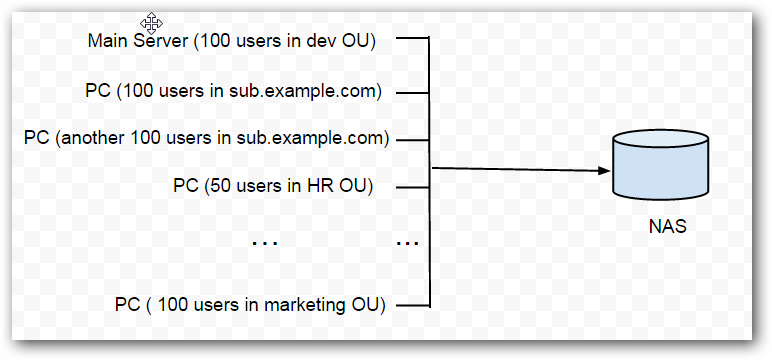
Assume there is a large Google Apps domain “example.com” with 1000 users, 200 of whom are located in the subdomain “sub.example.com”. There are also several organization units in the main domain (for example, 100 users in marketing 100 in dev, 50 in HR, etc.). The whole structure of the domain looks like this:

For such a large domain, a complete initial backup may be so enormous that it would take months to back up all the data locally, which, of course, is unacceptable. In most cases, a professional local storage unit, such as a NAS or SAN, will be used to store the backup data. Usually, these devices have excellent write speeds and are capable of handling very high data throughputs. In this case, you can split the users into different CubeBackup instances running on separate computers, while setting the backup location for each instance to the same NAS/SAN device. Since CubeBackup can be run on almost any computer, one powerful server and several low-speed desktop computers make a good combination for this strategy.
This parallel backup strategy can speed up the backup process tremendously. Since CubeBackup consumes very little memory and CPU resources, it can run in the background on almost any computer without interrupting the user. This makes it is very easy to add more computers to this kind of parallel backup system.
How many computers should be used to speed up the backup?
In most cases, the bottleneck of the parallel backup system lies in the speed of the NAS/SAN. Since most Gmail message backups are small files, the speed at which these small files can be written to local storage is the key factor in deciding how many computers can be added to the parallel system. Due to the wide spectrum in the performance of different storage devices, it is difficult to predict the optimal number of computers. We suggest starting small, with 4 computers, and then adding more running instances to the parallel backup system to find the best combination.
Merge all users into the main server after a few backups
Because CubeBackup employs an incremental backup algorithm, subsequent backups after the initial full backup only store new or modified data, which is much less time-consuming. Therefore, it shouldn’t be necessary to keep so many CubeBackup instances running after the first several backups; the main server should be sufficient to handle most of the load.
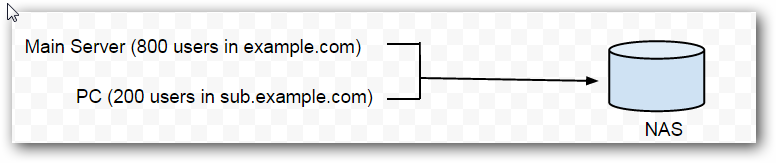
Another option for parallel backup:
In some cases, there is no NAS/SAN available within your company. Instead, each department is responsible for maintaining their own set of backup. In this situation, CubeBackup can be run directly on computers within the department, with backups split according to organizational units, like this:

This method does not require high-performance local storage and can use existing PCs for the backup. However, since there is no central data storage, and local storage within each PC is not as stable or reliable as a NAS/SAN, maintenance of the backup data may become a problem.
We plan to add parallel backup and multi-domain support in the next version of CubeBackup. If you have any suggestions for our product, please let us know!
“We plan to include parallel backup algorithm in the next version of CubeBackup…”
Since it has been a number of months since this was written, is parallel backups on the same computer been added yet?
The parallel backup will be added in version3.0. We are still working on it
Do we need more than one licence to run multiple CubeBackup instances?
No, as long as all instances are used to backup data for one organization, one license is enough.