How can Google Workspace backups be optimized for large organizations?
Large organizations may find that it can take a considerable amount of time for CubeBackup to complete the initial backup for all users and shared drives. This is especially true for organizations with thousands of users and a large number of Drive files or Gmail messages in their Google Workspace domain.
The first backup must download all data from your Google Workspace domain, but since CubeBackup employs incremental backups, subsequent backups will only download new or modified data. Thus, while it may take a long time to finish the first backup if there are many terabytes of data in your domain, later backups will complete much more quickly.
Best Practices for Large Organizations:
a. Consider running multiple CubeBackup instances on separate servers/VMs.
If there are more than 1,000 users in your Google Workspace domain, please consider splitting these users over several CubeBackup instances to speed up the backup process. CubeBackup supports selecting users based on their OUs to easily separate users in a domain.
Note:
1. Make sure to choose a different storage location (or a different bucket) for each instance to avoid serious data conflicts.
2. You can purchase one license for all users and activate it in multiple instances separately without extra cost or trouble.
For example, if you have 1,000 users and 1,000 shared drives, you can:
- Run CubeBackup on two EC2 instances, one of which backs up 500 users and 500 shared drives in OU(a) and the other one backs up the rest in OU(b). The backup data should be stored in different S3 buckets.
- Or run CubeBackup on 3 local servers/VMs, one of which backs up 500 users in OU(a), another backs up 500 users in OU(b) and the other backs up 1,000 shared drives. Each server should point to different local disks or different NAS partitions.
b. Store the data index on a local SSD.
The data index acts as a cache to speed up the backup process. Placing the data index on a fast local disk can greatly improve the backup speed. If you have put the data index on an HDD or a network storage, please consider changing it to a local SSD.
If CubeBackup runs on an AWS EC2 instance, consider using a Provisioned IOPS SSD (io1) volume to store the data index.
c. Make sure your backup server has at least 8GB of memory.
CubeBackup runs backup jobs in parallel. Usually more than 10 backup threads are running simultaneously, so it can consume quite a bit of memory. Although 4GB is often sufficient for small organizations, 8GB or above is strongly recommended for large organizations.
d. Run CubeBackup on a cloud instance and backup to cloud storage
Local storage can be fast, but for large organizations, CubeBackup runs even faster on a cloud instance while backing up directly to cloud storage from the same cloud service provider.
Most cloud storage simply has greater throughput capabilities than local storage. The network bandwidth is almost certainly much higher than your local network, plus there is no need to worry about a backup job consuming too much of your office network bandwidth. Generally, we recommend AWS EC2 instances paired with AWS S3, Google Cloud VM instances paired with Google Cloud storage, and Microsoft Azure Virtual Machines paired with Azure Blob storage.
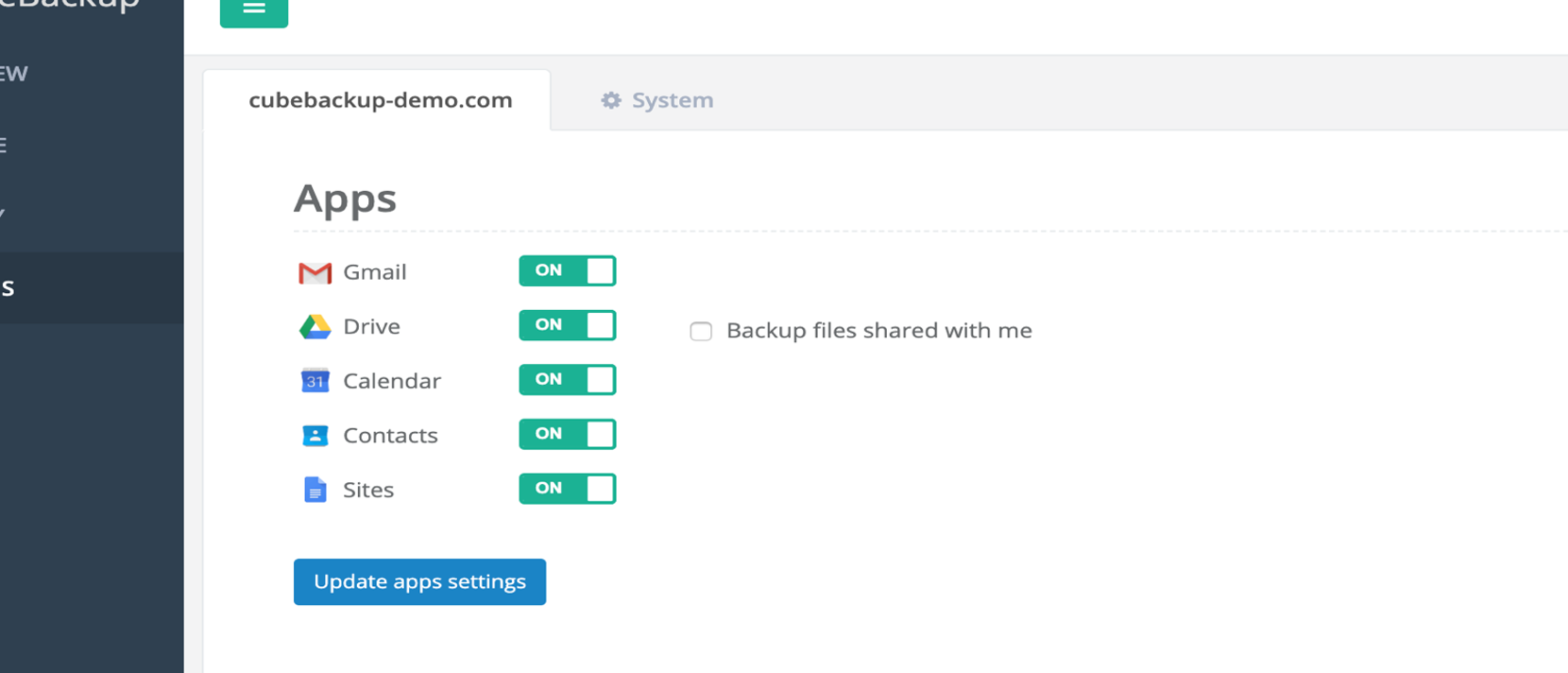
e. Ensure that the "Backup files shared with me" option is not enabled.
Enabling this option in CubeBackup may result in many duplications in the backup data. When this option is enabled, any files shared among users in the domain will be duplicated and stored separately for each user. This problem is greatly magnified in large organizations with hundreds or thousands of users.
Support
Last but not least, do not hesitate to contact us at [email protected] if you need help.